
Установка и настройка
Одной из самых интересных новых возможностей бесплатной платформы для серверной виртуализации Microsoft Hyper-V Server 2008 R2 является возможность работать в failover-кластере. В этой статье будет рассмотрен процесс создания кластера, а так же failover и Live Migration виртуальных машин внутри него.
Некоторые из читателей наверняка слышали о появлении у Microsoft бесплатного продукта для виртуализации серверов под названием Hyper-V Server. Представляет этот продукт из себя всего-навсего до максимума урезанную ОС Microsoft Windows Server 2008. В ней доступна всего лишь одна роль: Hyper-V, и отсутствует графический интерфейс – как в режиме установки Server Core. Управлять им можно через встроенную утилиту sconfig, через командную строку и удаленно через MMC. Недавно вышла новая версия этого замечательного продукта: Microsoft Windows Server 2008 R2. Что же в ней нового?
Во-первых, Hyper-V Server 2008 R2 поддерживает уже 8 процессоров и до 2Тб оперативной памяти, тогда как предыдущая версия поддерживала только до 4 процессоров и до 32Гб памяти. Во-вторых, новая версия поддерживает работу в составе Failover-кластера, и, соответственно – все вытекающие из этого возможности R2: Cluster Shared Volumes и Live Migration. Так же поддерживаются и другие новые возможности платформы R2, как VMQ, Core Parking и т.д. В-третьих – утилита конфигурации sconfig была во многом доработана, и теперь благодаря ней можно сделать все первоначальные настройки, такие, как сетевые настройки, ввод в домен, включение удаленного управления – прямо в sconfig, без использования командной строки.
С точки зрения лицензирования имеются следующие отличия: во-первых, сам Hyper-V Server, как уже было сказано – абсолютно бесплатен. Это значит, что не придется покупать никаких лицензий ни на сам сервер, ни клиентских лицензий для него, а так же не придется платить за какие-либо дополнительные штатные возможности, как, например, у VMWare.
Тем не менее, здесь у Windows Server есть одно важное преимущество: при покупке Windows Server 2008 предоставляется право бесплатного запуска (без покупки серверной лицензии) определенного числа гостевых ОС Windows Server в пределах одного физического хоста: одной – для версии Standard, до четырех – для Enterprisre и не ограниченное число гостевых Windows Server в версии Datacenter. В случае же с Hyper-V Server таких прав не предоставляется, и каждая гостевая ОС должна иметь лицензию. Поэтому Hyper-V Server совсем не обязательно может стать самым выгодным решением. К примеру, при миграции уже существующей инфраструктуры, когда на все серверные ОС уже куплены лицензии – бесплатный Hyper-V Server будет очень даже выгодным решением. Если же планируется развертывание инфраструктуры «с нуля» — то может оказаться выгоднее купить Windows Server 2008 EE или даже Datacenter в случае, если виртуальных машин будет достаточно много.
Системные требования для Hyper-V Server такие же, как и для Windows Server 2008 с поддержкой Hyper-V. Первое, о чем необходимо помнить – процессор должен быть 64-битной архитектуры, а так же поддерживать технологию аппаратной виртуализации (Intel VT или AMD-V) и аппаратную же Data Execution Prevention (у Intel это называется Execute Disable, XD-bit, а у AMD – No-Execute, NX-bit). Так же необходимо помнить, что обе эти возможности должны быть включены в BIOS Setup, в этом нужно убедиться перед установкой ОС. Если планируется работа в кластере – процессоры на всех узлах желательно должны быть одной модели. Или хотя бы одного производителя, в противном случае перенос виртуальных машин между узлами будет невозможен. Что касается оперативной памяти – тут все считается по достаточно простой формуле: суммарный объем памяти всех виртуальных машин, которые планируется запускать плюс 1 Гбайт для самой ОС. Если же планируем использование кластеров – то надо предусмотреть запас по объему памяти для запуска виртуальных машин, которые, возможно, будут перемещаться с одного узла на другой. Для работы Hyper-V Server 2008 R2 достаточно 8Gb свободного дискового пространства, поддерживается так же запуск с флэш-накопителей. Разумеется, понадобится некий объем дискового пространства для хранения файлов виртуальных машин. Если же планируется работа в кластере – то не обойтись без внешней системы хранения данных, работающей по протоколам FC, SAS или хотя бы iSCSI.
Официально поддерживаются в качестве гостевых следующие ОС:
· Разумеется – вся линейка ОС от Microsoft: от Windows 2000 Server до Windows Server 2008 R2, и от Windows XP до Windows 7
· Novell SUSE Linux Enterprise Server версий 10 и 11 с SP1/SP2
· Red Hat Enterprise Linux 5.2 и 5.3 с одним допущением: не будут поддерживаться компоненты интеграции, и соответственно – синтетические устройства, к примеру – улучшенная поддержка мыши или виртуальный Ethernet-адаптер 10Gbit.
Все остальные ОС, вполне возможно, что и запустятся в виртуальной среде, но только на ваш собственный страх и риск: официально со стороны Microsoft поддержки не будет. Если кому-нибудь удастся запустить на Hyper-V, к примеру, FreeBSD или Solaris – буду рад, если поделитесь опытом J
Статью можно разделить на три главы. В первой главе под названием «Прежде, чем двинуться дальше…» идет сухая теория: что такое «кластер» и с чем его едят, что есть Quick и Live Migration, что такое Cluster Shared Volumes. Если вы уже знаете все это – то можете переходить сразу ко второй главе – «От теории – к практике». И наконец, в третьей главе «Проверим» — описано, как сделать Live Migration и как происходит Failover запущенных виртуальных машин на другой узел.
Прежде, чем двинуться дальше…
…давайте вспомним, что же такое «кластер»
В терминологии Microsoft различают три вида кластеров: отказоустойчивый – failover, кластер балансировки сетевой нагрузки – NLB-cluster и кластер для высокопроизводительных вычислений – high-performance cluster, он же HPC. В настоящей статье речь будет идти об отказоустойчивых кластерах.
Для чего нужен отказоустойчивый кластер? Как ясно из названия – для повышения отказоустойчивости бизнес-критичных приложений. Например – базы данных. Или, в нашем случае – целой виртуальной машины. При использовании технологий отказоустойчивой кластеризации выход из строя одного физического сервера не приведет к отказу критичного приложения: приложение будет мгновенно, или же с небольшим простоем (до нескольких минут) перезапущено на другом сервере. Тем не менее, использование такой технологии приводит к сильному удорожанию системы: во-первых – из-за необходимости использовать два и более сервера там, где хватило бы и одного, во-вторых – из-за того, что для работы кластера необходима внешняя система хранения данных, которую придется приобрести, если таковых еще нет, и в-третьих – вполне возможно, что для использования технологий кластеризации придется приобрести более дорогие версии ПО (к Hyper-V Server не относится .
Итак, отказоустойчивый кластер состоит как минимум из двух серверов, которые именуются узлами кластера (nodes). Узлы кластера периодически обмениваются между собой особыми пакетами информации, именуемыми heartbeat. Если один из узлов выходит из строя – он перестает отсылать сигналы heartbeat, и кластер отмечает узел как «сбойный». При этом, если на сбойном узле были запущены критичные сервисы – то произойдет их автоматический перезапуск на одном из работающих узлов. В зависимости от сервиса, это может произойти вообще без простоя или же с минимальным простоем в несколько минут – что все равно лучше, чем тратить несколько часов на восстановление сервера.
Все узлы кластера используют общую систему хранения данных, на которой хранятся общие данные, необходимые для работы самого кластера (так называемый «кворум») и данные, необходимые для функционирования критичных сервисов (файлы БД, виртуальных машин, и т.д.). Хотя фактически кластер состоит из нескольких физических серверов – в сети он представляется как один виртуальный сервер, имеющий свое собственное сетевое имя и IP-адрес. Обращение к кластеризованному сервису производится с использованием собственного имени и IP-адреса кластера, и до тех пор, пока кластер функционирует – к сервисам можно обращаться по одному и тому же имени, вне зависимости от того, на каком из физических серверов запущены сервисы в данный момент времени.
Как уже было сказано – технологии кластеризации должны поддерживаться на уровне ПО: как самой ОС (Windows Server 2008 Enterprise / Datacenter, Hyper-V Server 2008 R2), так и на уровне прикладного ПО (например – Microsoft SQL Server).
Таки где же профит?
Что же даст использование отказоустойчивых кластеров при виртуализации? Разумеется, это повысит отказоустойчивость виртуальных машин: в случае выхода из строя одного из серверов все запущенные на нем виртуальные машины автоматически перезапустятся на другом узле, для гостевых ОС это будет выглядеть как некорректная перезагрузка. То есть 100%-й защиты от сбоев кластер не даст, простой в несколько минут все же произойдет, и несохраненные данные, если таковые имелись – будут потеряны, но все же это значительно быстрее, чем замена неисправного сервера с переносом виртуальных машин.
Quick and Live Migration
Кроме этого, использование отказоустойчивой кластеризации позволит переносить виртуальные машины с одного сервера на другой намного быстрее за счет технологий Quick Migration и Live Migration.
Технология Quick Migration работает следующим образом:
1. Перемещаемая виртуальная машина переводится в состояние Save State.
2. На сервере, куда планируется перемещать виртуальную машину – создается новая виртуальная машина с таким же именем и с такой же конфигурацией.
3. К созданной виртуальной машине монтируются все необходимые виртуальные диски.
4. Старая виртуальная машина удаляется.
5. Новая виртуальная машина запускается с восстановлением из Save State.
Этот способ перемещения имеет один серьезный недостаток: процесс перехода виртуальной машины в Save State и последующее восстановление занимает определенное время, в течение которого виртуальная машина остается недоступной. И, к примеру, если к ней подключались пользователи по RDP – произойдет обрыв сессии, что в принципе неприятно, но и не смертельно.
В Windows Server 2008 R2 появился новый способ перемещения под названием Live Migration. Происходит это следующим образом:
1. На сервере, куда планируется перемещать виртуальную машину – создается новая виртуальная машина с таким же именем и с такой же конфигурацией
2. Копирование содержимого памяти с переносимой виртуальной машины на вновь созданную. Копирование осуществляется циклически, и на каждом цикле копируются только те ячейки памяти, содержимое которых изменилось с момента предыдущего копирования. Виртуальная машина же при этом продолжает работать.
3. Как только содержимое памяти на обеих виртуальных машинах будет полностью совпадать – происходит перемонтирование всех виртуальных дисков к новой виртуальной машине.
4. Новая виртуальная машина теперь работает, а старая – удаляется.
Поскольку при Live Migration содержимое памяти копируется «на лету», без останова виртуальной машины – то время простоя фактически равно нулю. Небольшой, размером в малые доли секунды, простой будет на этапе перемонтирования виртуальных дисков, но он будет незаметен для пользователя, так как TCP-сессии за этот момент не успеют оборваться по тайм-ауту. Тем не менее, здесь имеется небольшой нюанс: копирование содержимого памяти осуществляется по сети, и длительность процесса зависит от нагруженности сети. Поэтому, если сеть достаточно сильно загружена – рекомендуется добавить на серверах дополнительные сетевые интерфейсы и создать отдельную сеть исключительно для трафика при миграции. Так же надо помнить, что существует ограничение в 10 циклов при копировании содержимого памяти. То есть, если содержимое памяти очень часто и очень сильно меняется (к примеру – база данных с очень большим количеством транзакций в секунду), и/или из-за загруженности сети копирование происходит достаточно медленно – миграция может не произойти вообще.
Cluster Shared Volumes
Прежде, чем перейти к практике – нужно сказать еще об одной новой возможности в Windows Server 2008 R2: кластерной файловой системе, Cluster Shared Volumes (CSV).
Без использования кластерных ФС два узла кластера не могут обращаться одновременно к одному и тому же дисковому устройству: при обращении к нему с одного из серверов на другом устройство переходит в состояние Offline. Поэтому до появления CSV было очень сложно запускать одновременно несколько виртуальных машин на разных узлах кластера: для этого приходилось для каждой виртуальной машины создавать свой отдельный LUN, что создавало дополнительные сложности. С использованием же CSV эта проблема решается: CSV позволяет осуществлять одновременный доступ к данным на одном дисковом устройстве с нескольких серверов.
Тома CSV не имеют в системе своих букв. Вместо этого, они на манер UNIX-like монтируются как папки в системном разделе. При использовании CSV на системном диске (как правило, это диск C: ) создается папка ClusterStorage, и все дисковые устройства, используемые как CSV, монтируются в ней как подпапки в виде C:\ClusterStorage\volume1, C:\ClusterStorage\volume2, …, C:\ClusterStorage\volumeN. В связи с этим необходимо учитывать, что на всех узлах кластера системный раздел должен иметь одинаковую букву. Так же необходимо учитывать, что CSV в настоящий момент официально поддерживаются только в качестве хранилища данных для виртуальных машин Hyper-V.
От теории – к практике
Вы все еще не устали читать? Поздравляю. Теперь мы посмотрим, как это все работает на «реальном железе».
Итак, для демонстрации работы кластера на Hyper-V Server 2008 R2 была создана тестовая инфраструктура, состоящая из трех физических машин:
· Node1 – будет использоваться в качестве первого узла кластера
· Node2 – будет использоваться в качестве второго узла кластера
· Server – хост для запуска виртуальной машины DC
Как нетрудно догадаться, на Node1 и Node2 установлен Hyper-V Server 2008 R2, а на Server – Windows Server 2008 R2 с ролью Hyper-V. Виртуальная машина DC, запущенная на Server, используется во-первых – в качестве контроллера домена TEST.LOCAL, а во-вторых – в качестве системы хранения данных. Для этого на ней установлено ПО Starwind iSCSI Target в бесплатной версии. Бесплатная версия позволяет создавать iSCSI targets объемом до 2Tb, но надо помнить, что использовать в продакшене ее нельзя. Для нашей демонстрации было создано два виртуальных дисковых устройства: объемом 0,5Gb и 20Gb, впоследствии подключенные к Node1 и Node2 с использованием iSCSI. Устройство меньшего объема будет использоваться в качестве кворумного ресурса для работы кластера, а большего – для хранения данных виртуальных машин.
Все сервера объединены сетью Gigabit Ethernet, Node1 и Node2 являются членами домена TEST.LOCAL.
Схема нашей тестовой инфраструктуры выглядит следующим образом:
Некоторые из читателей наверняка слышали о появлении у Microsoft бесплатного продукта для виртуализации серверов под названием Hyper-V Server. Представляет этот продукт из себя всего-навсего до максимума урезанную ОС Microsoft Windows Server 2008. В ней доступна всего лишь одна роль: Hyper-V, и отсутствует графический интерфейс – как в режиме установки Server Core. Управлять им можно через встроенную утилиту sconfig, через командную строку и удаленно через MMC. Недавно вышла новая версия этого замечательного продукта: Microsoft Windows Server 2008 R2. Что же в ней нового?
Во-первых, Hyper-V Server 2008 R2 поддерживает уже 8 процессоров и до 2Тб оперативной памяти, тогда как предыдущая версия поддерживала только до 4 процессоров и до 32Гб памяти. Во-вторых, новая версия поддерживает работу в составе Failover-кластера, и, соответственно – все вытекающие из этого возможности R2: Cluster Shared Volumes и Live Migration. Так же поддерживаются и другие новые возможности платформы R2, как VMQ, Core Parking и т.д. В-третьих – утилита конфигурации sconfig была во многом доработана, и теперь благодаря ней можно сделать все первоначальные настройки, такие, как сетевые настройки, ввод в домен, включение удаленного управления – прямо в sconfig, без использования командной строки.
С точки зрения лицензирования имеются следующие отличия: во-первых, сам Hyper-V Server, как уже было сказано – абсолютно бесплатен. Это значит, что не придется покупать никаких лицензий ни на сам сервер, ни клиентских лицензий для него, а так же не придется платить за какие-либо дополнительные штатные возможности, как, например, у VMWare.
Тем не менее, здесь у Windows Server есть одно важное преимущество: при покупке Windows Server 2008 предоставляется право бесплатного запуска (без покупки серверной лицензии) определенного числа гостевых ОС Windows Server в пределах одного физического хоста: одной – для версии Standard, до четырех – для Enterprisre и не ограниченное число гостевых Windows Server в версии Datacenter. В случае же с Hyper-V Server таких прав не предоставляется, и каждая гостевая ОС должна иметь лицензию. Поэтому Hyper-V Server совсем не обязательно может стать самым выгодным решением. К примеру, при миграции уже существующей инфраструктуры, когда на все серверные ОС уже куплены лицензии – бесплатный Hyper-V Server будет очень даже выгодным решением. Если же планируется развертывание инфраструктуры «с нуля» — то может оказаться выгоднее купить Windows Server 2008 EE или даже Datacenter в случае, если виртуальных машин будет достаточно много.
Системные требования для Hyper-V Server такие же, как и для Windows Server 2008 с поддержкой Hyper-V. Первое, о чем необходимо помнить – процессор должен быть 64-битной архитектуры, а так же поддерживать технологию аппаратной виртуализации (Intel VT или AMD-V) и аппаратную же Data Execution Prevention (у Intel это называется Execute Disable, XD-bit, а у AMD – No-Execute, NX-bit). Так же необходимо помнить, что обе эти возможности должны быть включены в BIOS Setup, в этом нужно убедиться перед установкой ОС. Если планируется работа в кластере – процессоры на всех узлах желательно должны быть одной модели. Или хотя бы одного производителя, в противном случае перенос виртуальных машин между узлами будет невозможен. Что касается оперативной памяти – тут все считается по достаточно простой формуле: суммарный объем памяти всех виртуальных машин, которые планируется запускать плюс 1 Гбайт для самой ОС. Если же планируем использование кластеров – то надо предусмотреть запас по объему памяти для запуска виртуальных машин, которые, возможно, будут перемещаться с одного узла на другой. Для работы Hyper-V Server 2008 R2 достаточно 8Gb свободного дискового пространства, поддерживается так же запуск с флэш-накопителей. Разумеется, понадобится некий объем дискового пространства для хранения файлов виртуальных машин. Если же планируется работа в кластере – то не обойтись без внешней системы хранения данных, работающей по протоколам FC, SAS или хотя бы iSCSI.
Официально поддерживаются в качестве гостевых следующие ОС:
· Разумеется – вся линейка ОС от Microsoft: от Windows 2000 Server до Windows Server 2008 R2, и от Windows XP до Windows 7
· Novell SUSE Linux Enterprise Server версий 10 и 11 с SP1/SP2
· Red Hat Enterprise Linux 5.2 и 5.3 с одним допущением: не будут поддерживаться компоненты интеграции, и соответственно – синтетические устройства, к примеру – улучшенная поддержка мыши или виртуальный Ethernet-адаптер 10Gbit.
Все остальные ОС, вполне возможно, что и запустятся в виртуальной среде, но только на ваш собственный страх и риск: официально со стороны Microsoft поддержки не будет. Если кому-нибудь удастся запустить на Hyper-V, к примеру, FreeBSD или Solaris – буду рад, если поделитесь опытом J
Статью можно разделить на три главы. В первой главе под названием «Прежде, чем двинуться дальше…» идет сухая теория: что такое «кластер» и с чем его едят, что есть Quick и Live Migration, что такое Cluster Shared Volumes. Если вы уже знаете все это – то можете переходить сразу ко второй главе – «От теории – к практике». И наконец, в третьей главе «Проверим» — описано, как сделать Live Migration и как происходит Failover запущенных виртуальных машин на другой узел.
Прежде, чем двинуться дальше…
…давайте вспомним, что же такое «кластер»
В терминологии Microsoft различают три вида кластеров: отказоустойчивый – failover, кластер балансировки сетевой нагрузки – NLB-cluster и кластер для высокопроизводительных вычислений – high-performance cluster, он же HPC. В настоящей статье речь будет идти об отказоустойчивых кластерах.
Для чего нужен отказоустойчивый кластер? Как ясно из названия – для повышения отказоустойчивости бизнес-критичных приложений. Например – базы данных. Или, в нашем случае – целой виртуальной машины. При использовании технологий отказоустойчивой кластеризации выход из строя одного физического сервера не приведет к отказу критичного приложения: приложение будет мгновенно, или же с небольшим простоем (до нескольких минут) перезапущено на другом сервере. Тем не менее, использование такой технологии приводит к сильному удорожанию системы: во-первых – из-за необходимости использовать два и более сервера там, где хватило бы и одного, во-вторых – из-за того, что для работы кластера необходима внешняя система хранения данных, которую придется приобрести, если таковых еще нет, и в-третьих – вполне возможно, что для использования технологий кластеризации придется приобрести более дорогие версии ПО (к Hyper-V Server не относится .
Итак, отказоустойчивый кластер состоит как минимум из двух серверов, которые именуются узлами кластера (nodes). Узлы кластера периодически обмениваются между собой особыми пакетами информации, именуемыми heartbeat. Если один из узлов выходит из строя – он перестает отсылать сигналы heartbeat, и кластер отмечает узел как «сбойный». При этом, если на сбойном узле были запущены критичные сервисы – то произойдет их автоматический перезапуск на одном из работающих узлов. В зависимости от сервиса, это может произойти вообще без простоя или же с минимальным простоем в несколько минут – что все равно лучше, чем тратить несколько часов на восстановление сервера.
Все узлы кластера используют общую систему хранения данных, на которой хранятся общие данные, необходимые для работы самого кластера (так называемый «кворум») и данные, необходимые для функционирования критичных сервисов (файлы БД, виртуальных машин, и т.д.). Хотя фактически кластер состоит из нескольких физических серверов – в сети он представляется как один виртуальный сервер, имеющий свое собственное сетевое имя и IP-адрес. Обращение к кластеризованному сервису производится с использованием собственного имени и IP-адреса кластера, и до тех пор, пока кластер функционирует – к сервисам можно обращаться по одному и тому же имени, вне зависимости от того, на каком из физических серверов запущены сервисы в данный момент времени.
Как уже было сказано – технологии кластеризации должны поддерживаться на уровне ПО: как самой ОС (Windows Server 2008 Enterprise / Datacenter, Hyper-V Server 2008 R2), так и на уровне прикладного ПО (например – Microsoft SQL Server).
Таки где же профит?
Что же даст использование отказоустойчивых кластеров при виртуализации? Разумеется, это повысит отказоустойчивость виртуальных машин: в случае выхода из строя одного из серверов все запущенные на нем виртуальные машины автоматически перезапустятся на другом узле, для гостевых ОС это будет выглядеть как некорректная перезагрузка. То есть 100%-й защиты от сбоев кластер не даст, простой в несколько минут все же произойдет, и несохраненные данные, если таковые имелись – будут потеряны, но все же это значительно быстрее, чем замена неисправного сервера с переносом виртуальных машин.
Quick and Live Migration
Кроме этого, использование отказоустойчивой кластеризации позволит переносить виртуальные машины с одного сервера на другой намного быстрее за счет технологий Quick Migration и Live Migration.
Технология Quick Migration работает следующим образом:
1. Перемещаемая виртуальная машина переводится в состояние Save State.
2. На сервере, куда планируется перемещать виртуальную машину – создается новая виртуальная машина с таким же именем и с такой же конфигурацией.
3. К созданной виртуальной машине монтируются все необходимые виртуальные диски.
4. Старая виртуальная машина удаляется.
5. Новая виртуальная машина запускается с восстановлением из Save State.
Этот способ перемещения имеет один серьезный недостаток: процесс перехода виртуальной машины в Save State и последующее восстановление занимает определенное время, в течение которого виртуальная машина остается недоступной. И, к примеру, если к ней подключались пользователи по RDP – произойдет обрыв сессии, что в принципе неприятно, но и не смертельно.
В Windows Server 2008 R2 появился новый способ перемещения под названием Live Migration. Происходит это следующим образом:
1. На сервере, куда планируется перемещать виртуальную машину – создается новая виртуальная машина с таким же именем и с такой же конфигурацией
2. Копирование содержимого памяти с переносимой виртуальной машины на вновь созданную. Копирование осуществляется циклически, и на каждом цикле копируются только те ячейки памяти, содержимое которых изменилось с момента предыдущего копирования. Виртуальная машина же при этом продолжает работать.
3. Как только содержимое памяти на обеих виртуальных машинах будет полностью совпадать – происходит перемонтирование всех виртуальных дисков к новой виртуальной машине.
4. Новая виртуальная машина теперь работает, а старая – удаляется.
Поскольку при Live Migration содержимое памяти копируется «на лету», без останова виртуальной машины – то время простоя фактически равно нулю. Небольшой, размером в малые доли секунды, простой будет на этапе перемонтирования виртуальных дисков, но он будет незаметен для пользователя, так как TCP-сессии за этот момент не успеют оборваться по тайм-ауту. Тем не менее, здесь имеется небольшой нюанс: копирование содержимого памяти осуществляется по сети, и длительность процесса зависит от нагруженности сети. Поэтому, если сеть достаточно сильно загружена – рекомендуется добавить на серверах дополнительные сетевые интерфейсы и создать отдельную сеть исключительно для трафика при миграции. Так же надо помнить, что существует ограничение в 10 циклов при копировании содержимого памяти. То есть, если содержимое памяти очень часто и очень сильно меняется (к примеру – база данных с очень большим количеством транзакций в секунду), и/или из-за загруженности сети копирование происходит достаточно медленно – миграция может не произойти вообще.
Cluster Shared Volumes
Прежде, чем перейти к практике – нужно сказать еще об одной новой возможности в Windows Server 2008 R2: кластерной файловой системе, Cluster Shared Volumes (CSV).
Без использования кластерных ФС два узла кластера не могут обращаться одновременно к одному и тому же дисковому устройству: при обращении к нему с одного из серверов на другом устройство переходит в состояние Offline. Поэтому до появления CSV было очень сложно запускать одновременно несколько виртуальных машин на разных узлах кластера: для этого приходилось для каждой виртуальной машины создавать свой отдельный LUN, что создавало дополнительные сложности. С использованием же CSV эта проблема решается: CSV позволяет осуществлять одновременный доступ к данным на одном дисковом устройстве с нескольких серверов.
Тома CSV не имеют в системе своих букв. Вместо этого, они на манер UNIX-like монтируются как папки в системном разделе. При использовании CSV на системном диске (как правило, это диск C: ) создается папка ClusterStorage, и все дисковые устройства, используемые как CSV, монтируются в ней как подпапки в виде C:\ClusterStorage\volume1, C:\ClusterStorage\volume2, …, C:\ClusterStorage\volumeN. В связи с этим необходимо учитывать, что на всех узлах кластера системный раздел должен иметь одинаковую букву. Так же необходимо учитывать, что CSV в настоящий момент официально поддерживаются только в качестве хранилища данных для виртуальных машин Hyper-V.
От теории – к практике
Вы все еще не устали читать? Поздравляю. Теперь мы посмотрим, как это все работает на «реальном железе».
Итак, для демонстрации работы кластера на Hyper-V Server 2008 R2 была создана тестовая инфраструктура, состоящая из трех физических машин:
· Node1 – будет использоваться в качестве первого узла кластера
· Node2 – будет использоваться в качестве второго узла кластера
· Server – хост для запуска виртуальной машины DC
Как нетрудно догадаться, на Node1 и Node2 установлен Hyper-V Server 2008 R2, а на Server – Windows Server 2008 R2 с ролью Hyper-V. Виртуальная машина DC, запущенная на Server, используется во-первых – в качестве контроллера домена TEST.LOCAL, а во-вторых – в качестве системы хранения данных. Для этого на ней установлено ПО Starwind iSCSI Target в бесплатной версии. Бесплатная версия позволяет создавать iSCSI targets объемом до 2Tb, но надо помнить, что использовать в продакшене ее нельзя. Для нашей демонстрации было создано два виртуальных дисковых устройства: объемом 0,5Gb и 20Gb, впоследствии подключенные к Node1 и Node2 с использованием iSCSI. Устройство меньшего объема будет использоваться в качестве кворумного ресурса для работы кластера, а большего – для хранения данных виртуальных машин.
Все сервера объединены сетью Gigabit Ethernet, Node1 и Node2 являются членами домена TEST.LOCAL.
Схема нашей тестовой инфраструктуры выглядит следующим образом:

Установка
Начнем с установки. УСТАНАВЛИВАЙТЕ АНГЛИЙСКУЮ ВЕРСИЮ!!!!!
Установка с компакт-диска не представляет собой ничего сложного — загрузились с диска, выбрали язык, согласились с лицензионным соглашением, выбрали раздел и «ушли курить» минут на 10. (Лучше конечно сделать загрузочную флешку)
Начнем с установки. УСТАНАВЛИВАЙТЕ АНГЛИЙСКУЮ ВЕРСИЮ!!!!!
Установка с компакт-диска не представляет собой ничего сложного — загрузились с диска, выбрали язык, согласились с лицензионным соглашением, выбрали раздел и «ушли курить» минут на 10. (Лучше конечно сделать загрузочную флешку)

После установки появятся два окошечка синее для настроек и обычное cmd
 1) Для начала закинем компьютер в домен и присвоем ему имя. (ребут)
1) Для начала закинем компьютер в домен и присвоем ему имя. (ребут)
2) Потом я бы посоветовал его обновить.
3) Переходим в 4 меню настройки удаленного управления включаем там mmc powershell и удаленное управление.
4) Переходим в 7 пункт меню и включаем RDP.
5) 11 меню включаем кластер.
ребут.
Для управления сервером вам потребуется скачать и установить Remote Server Administration Tools (RSAT) для клиентской операционной системы и установить компонент Диспетчер Hyper-V, или добавить роль Hyper-V и установить компонент Диспетчер Hyper-V на Windows Server 2008 R2.
Пытаемся подключиться к нашему серверу и видим ошибку, которая говорит нам занести админу пива, чтобы он выдал нужные права. Вспомнив, что мы и есть тот самый админ, не падаем духом и читаем дальше.
John Howard, который занимает пост Senior Program Manager in the Hyper-V team at Microsoft, написал цикл статей, посвященный раздаче необходимых прав, а в последствии состряпал замечательную утилиту HVRemote, которая произведет хитроумную настройку сервера и клиента, не взрывая мозг админу.
Ей мы и воспользуемся. Итак, скачиваем, заходим на сервер по \\server\C$, кладем HVremote.wsf в папку Windows (или в любое другое место, но тогда не забываем указывать полный путь до нее). Запускаем на сервере:
cscript hvremote.wsf /add:domain\account ***, где domain\account – ваше имя пользователя в домене. Скрипт пропишет все необходимые привилегии, в том числе откроет нужные порты на фаерволе.
Затем, на клиенте cscript hvremote.wsf /mmc:enable, скрипт создаст исключения фаервола.
Теперь можно запускать Диспетчер Hyper-V и подключаться к нашему серверу, создавать виртуалки и радоваться жизни.
Еще после установки RSAT если не получается подключиться с клиентского компа к службе управления виртуальными дисками, нужно проверить в брандмауэре включены ли две службы
Настраиваем второй компьютер аналогично.
Потом на DC устанавливаем StarWind.
Теперь нужно настроить ISCSI. Устанавливаем Starwind либо Windowый.
Покажу пример на Starwind
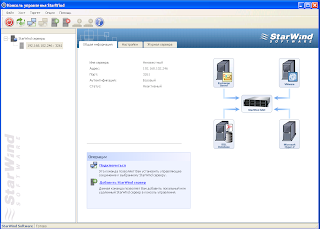
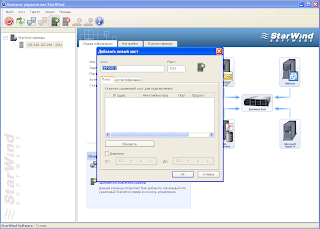
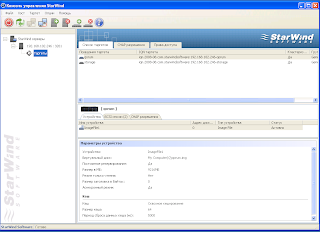
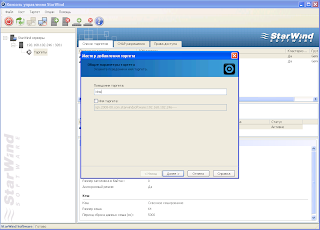
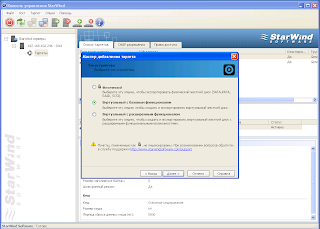

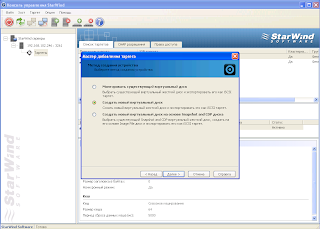
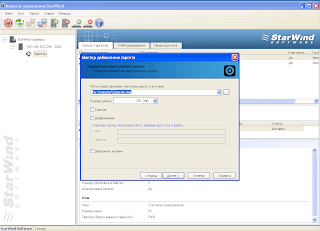 Нужно создать кворум гигов 5 и стораж гогов 40 либо меньше либо больше.
Нужно создать кворум гигов 5 и стораж гогов 40 либо меньше либо больше.
Теперь нам осталось подключить iSCSI-диски. Кто-то спрашивал, зачем в режиме Server Core нужна мышка? Переходим в командную строку и запускаем Microsoft iSCSI Initiator командой iscsicpl. Соглашаемся с запуском сервиса iSCSI и видим окно инициатора:
 Добавляем наш DC в Discovery Portal. Для этого на закладке Discovery нажимаем кнопку, как не трудно догадаться, Discovery Portal, и вбиваем сетевое имя нашего iSCSI-сервера, в нашем случае – DC.
Добавляем наш DC в Discovery Portal. Для этого на закладке Discovery нажимаем кнопку, как не трудно догадаться, Discovery Portal, и вбиваем сетевое имя нашего iSCSI-сервера, в нашем случае – DC.
Сразу после этого на закладке Targets должны появиться iSCSI-устройства, доступные на сервере. В нашем случае их будет целых два:
 Их необходимо подключить кнопкой Connect, а затем перейти на закладку Volumes and Devices и выбрать Auto Configure.
Их необходимо подключить кнопкой Connect, а затем перейти на закладку Volumes and Devices и выбрать Auto Configure.
Вроде как все. Но не совсем. Дело в том, что дальше нам придется подключаться к узлу через консоль MMC, но нас будет ждать облом? Кто угадает почему – может взять с полочки пирожок.
Все дело в том, что когда мы создавали виртуальную сеть – был создан новый сетевой адаптер, и на него были перенесены все сетевые настройки. Включая и настройки фаерволла. Поэтому нам необходимо повторить ( в меню sconfig пункт 4, затем 1 и 3).
Вот теперь все. Можно разлогиниться.
Мы находимся в интерфейсе виртуальной машины DC. Открываем консоль Server Manager, подключаемся к Node1 и идем Storage – Disk Management. Нам тут же предлагают проинициализировать наши два новых диска, что мы и делаем. После инициализации на каждом из дисков создаем раздел объемом на весь диск и форматируем. Файловая система, разумеется, NTFS. Размер кластера я для тестовой среды оставил дефолтным. 0,5Gb-диску я присвоил букву Q: и метку Quorum, а другому, соответственно – S: и Storage. Хотя это и не существенно, можно выбирать любые. После форматирования выглядело все вот так:
 Теперь можно и нужно подготовить второй узел: заходим на Node2, устанавливаем компоненту Failover Clustering, подключаем iSCSI-диски и включаем удаленное управление еще раз – по аналогии с действиями на Node1.
Теперь можно и нужно подготовить второй узел: заходим на Node2, устанавливаем компоненту Failover Clustering, подключаем iSCSI-диски и включаем удаленное управление еще раз – по аналогии с действиями на Node1.
Проверяем Server Manager’ом подключение iSCSI-дисков на Node2. Диски подключились, правда буквы им были выданы другие – D: и F:. Можно для проформы поменять их на Q: и S:, можно этого и не делать.
Собираем кластер
Наконец-то мы добрались собственно до сборки кластера. Все операции с кластером будут осуществляться через консоль Failover Cluster Managemer (далее – FCM).
Итак, мы открыли FCM. Первое, что нам необходимо сделать – это проверить, «взлетит или не взлетит», то есть соберется ли кластер из наших узлов или нет. Для этого используется мастер

Все, что здесь необходимо сделать – это выбрать сервера, которые будут входить в кластер, и выбрать тесты из списка. Тестов много, и я рекомендую провести их все – потому что только в случае успешного прохождения всех тестов решение будет поддерживаемым. Если все прошло успешно – то будет примерно такая картинка (Testing has completed successfully):
 В моем случае был один варнинг по причине того, что между серверами был всего лишь один сетевой линк, а рекомендуется – два и более. Но это в принципе не критично для тестовой инфраструктуры, поэтому будем считать тест пройденным успешно.
В моем случае был один варнинг по причине того, что между серверами был всего лишь один сетевой линк, а рекомендуется – два и более. Но это в принципе не критично для тестовой инфраструктуры, поэтому будем считать тест пройденным успешно.
Вы все еще не уснули? Тогда переходим непосредственно к сборке кластера. Запускаем мастер сборки (Create a Cluster). Мастер этот похож на предыдущий, так же будет необходимо выбрать наши узлы Node1 и Node2, а затем – задать сетевое имя и IP-адрес для самого кластера:
 После окончания процесса сборки наш кластер появится в дереве FCM:
После окончания процесса сборки наш кластер появится в дереве FCM:
2) Потом я бы посоветовал его обновить.
3) Переходим в 4 меню настройки удаленного управления включаем там mmc powershell и удаленное управление.
4) Переходим в 7 пункт меню и включаем RDP.
5) 11 меню включаем кластер.
ребут.
Для управления сервером вам потребуется скачать и установить Remote Server Administration Tools (RSAT) для клиентской операционной системы и установить компонент Диспетчер Hyper-V, или добавить роль Hyper-V и установить компонент Диспетчер Hyper-V на Windows Server 2008 R2.
Пытаемся подключиться к нашему серверу и видим ошибку, которая говорит нам занести админу пива, чтобы он выдал нужные права. Вспомнив, что мы и есть тот самый админ, не падаем духом и читаем дальше.
John Howard, который занимает пост Senior Program Manager in the Hyper-V team at Microsoft, написал цикл статей, посвященный раздаче необходимых прав, а в последствии состряпал замечательную утилиту HVRemote, которая произведет хитроумную настройку сервера и клиента, не взрывая мозг админу.
Ей мы и воспользуемся. Итак, скачиваем, заходим на сервер по \\server\C$, кладем HVremote.wsf в папку Windows (или в любое другое место, но тогда не забываем указывать полный путь до нее). Запускаем на сервере:
cscript hvremote.wsf /add:domain\account ***, где domain\account – ваше имя пользователя в домене. Скрипт пропишет все необходимые привилегии, в том числе откроет нужные порты на фаерволе.
Затем, на клиенте cscript hvremote.wsf /mmc:enable, скрипт создаст исключения фаервола.
Теперь можно запускать Диспетчер Hyper-V и подключаться к нашему серверу, создавать виртуалки и радоваться жизни.
Еще после установки RSAT если не получается подключиться с клиентского компа к службе управления виртуальными дисками, нужно проверить в брандмауэре включены ли две службы

Настраиваем второй компьютер аналогично.
Потом на DC устанавливаем StarWind.
Теперь нужно настроить ISCSI. Устанавливаем Starwind либо Windowый.
Покажу пример на Starwind








Теперь нам осталось подключить iSCSI-диски. Кто-то спрашивал, зачем в режиме Server Core нужна мышка? Переходим в командную строку и запускаем Microsoft iSCSI Initiator командой iscsicpl. Соглашаемся с запуском сервиса iSCSI и видим окно инициатора:
Сразу после этого на закладке Targets должны появиться iSCSI-устройства, доступные на сервере. В нашем случае их будет целых два:
Вроде как все. Но не совсем. Дело в том, что дальше нам придется подключаться к узлу через консоль MMC, но нас будет ждать облом? Кто угадает почему – может взять с полочки пирожок.
Все дело в том, что когда мы создавали виртуальную сеть – был создан новый сетевой адаптер, и на него были перенесены все сетевые настройки. Включая и настройки фаерволла. Поэтому нам необходимо повторить ( в меню sconfig пункт 4, затем 1 и 3).
Вот теперь все. Можно разлогиниться.
Мы находимся в интерфейсе виртуальной машины DC. Открываем консоль Server Manager, подключаемся к Node1 и идем Storage – Disk Management. Нам тут же предлагают проинициализировать наши два новых диска, что мы и делаем. После инициализации на каждом из дисков создаем раздел объемом на весь диск и форматируем. Файловая система, разумеется, NTFS. Размер кластера я для тестовой среды оставил дефолтным. 0,5Gb-диску я присвоил букву Q: и метку Quorum, а другому, соответственно – S: и Storage. Хотя это и не существенно, можно выбирать любые. После форматирования выглядело все вот так:
Проверяем Server Manager’ом подключение iSCSI-дисков на Node2. Диски подключились, правда буквы им были выданы другие – D: и F:. Можно для проформы поменять их на Q: и S:, можно этого и не делать.
Собираем кластер
Наконец-то мы добрались собственно до сборки кластера. Все операции с кластером будут осуществляться через консоль Failover Cluster Managemer (далее – FCM).
Итак, мы открыли FCM. Первое, что нам необходимо сделать – это проверить, «взлетит или не взлетит», то есть соберется ли кластер из наших узлов или нет. Для этого используется мастер
Все, что здесь необходимо сделать – это выбрать сервера, которые будут входить в кластер, и выбрать тесты из списка. Тестов много, и я рекомендую провести их все – потому что только в случае успешного прохождения всех тестов решение будет поддерживаемым. Если все прошло успешно – то будет примерно такая картинка (Testing has completed successfully):
Вы все еще не уснули? Тогда переходим непосредственно к сборке кластера. Запускаем мастер сборки (Create a Cluster). Мастер этот похож на предыдущий, так же будет необходимо выбрать наши узлы Node1 и Node2, а затем – задать сетевое имя и IP-адрес для самого кластера:

Разных опций и настроек у нас много. Вначале нужно посмотреть на раздел Nodes, проверить, что оба узла в состоянии Up (работают), а в разделе Storage – убедиться, что диск Q: назначен кворумом, а 20Gb-диск появился в Available Storage:

Создаем CSV
Теперь попробуем создать Cluster Shared Volume, на котором будем хранить наши виртуальные машины. Для этого заходим в корень консоли FCM и выбираем Enable Cluster Shared Volumes. Нас предупредят, что CSV разрешается использовать только для хранения файлов виртуальных машин Hyper-V, все остальное – unsupported solution:

После согласия с этим предупреждением в дереве настроек нашего кластера появится новый раздел с названием… ни за что не угадаете… Cluster Shared Volumes! Заходим туда и добавляем (Add Storage) наш диск S: объемом 20Gb в CSV:

Создаем виртуальную машину как сервис кластера
Кластер готов, теперь можно перейти к экспериментам. Для этого создадим виртуальную машину. Это можно сделать через оснастку Hyper-V Manager, но проще сделать через FCM – тем более, что туда все равно придется вернуться, чтобы сделать нашу виртуальную машину ресурсом кластера. В разделе Services and applications есть опция Virtual Machines, через которую мы и создаем нашу тестовую виртуальную машину, например, на узле Node1:

Запускается стандартный мастер создания виртуальной машины, такой же, как и в Hyper-V Manager. Мы будем хранить наши виртуальные машины на CSV, и поэтому надо указать соответствующий путь (C:\ClusterStorage\volume1):

В остальном – все полностью аналогично созданию виртуальной машины в Hyper-V Manager. Отмечу лишь, что назвали мы нашу машину TestVM, дали ей 512Mb памяти и диск фиксированного объема 15Gb.
Запускаем виртуальную машину, устанавливаем ОС. Отсюда же, из FCM, подключаемся к ее консоли (Connect to virtual machines) и проходим процесс установки ОС и ее настройки (сетевые настройки, ввод в домен, etc.)
Проверим?
Давайте теперь проверим, как работает Live Migration. Для этого на нашей тестовой виртуальной машине создадим расшаренную папку и начнем копировать в нее некий файл большого объема (к примеру – тот самый ISO-образ, с которого была установлена ОС). В процессе копирования переместим виртуальную машину с узла Node1 на Node2 с помощью Live Migration:

Как мы видим – процесс миграции занимает несколько секунд, а копирование файла при этом не прерывается.
Для проверки Failover можно, например, выдернуть сетевой кабель из одного из серверов кластера. В течении нескольких минут кластер «заметит», что узел «вышел из строя» (то есть перестал отправлять сигналы heartbeat) и если на нем были запущены виртуальные машины – перезапустит их на другом узле. Для гостевых ОС на перезапущенных виртуальных машинах это будет выглядеть как неожиданное выключение:

Таким образом, полной отказоустойчивости использование Failover Clustering обеспечить не может, но тем не менее failover в течение нескольких минут – это все же лучше, чем ручная замена сервера и перенос виртуальных машин в течение нескольких часов.
Удаление и проблемы.
Если вы удалили кластер и пытаетесь пересоздать его с теме же узлами но выходит ошибка что они уже являются частью кластера. Необходимо.
Принудительное исключение узла из отказоустойчивого кластера Windows Server 2003 с помощью средства Cluster.exe
Остановите службу кластеров, выполнив следующую команду:
net stop clussvc
После остановки службы кластеров принудительно исключите узел, выполнив следующую команду:
Остановите службу кластеров, выполнив следующую команду:
net stop clussvc
После остановки службы кластеров принудительно исключите узел, выполнив следующую команду:
Cluster <ClusterName> node <NodeName> /force
В моем случае cluster.exe cluster node cluster4 /force
Как мы убедились в этой статье, Hyper-V Server 2008 R2 вполне подходит для промышленного применения: он поддерживает все возможности Hyper-V R2 и может работать в составе отказоустойчивого кластера. Здесь мы на практике ознакомились с процессом развертывания failover-кластера на базе Hyper-V Server и проверили работу Live Migration и Failover. На вопрос что же лучше использовать в качестве среды для виртуализации – Windows Server или Hyper-V Server – однозначный ответ дать невозможно. Windows Server поддерживает работу в составе кластера только в версиях Enterprise и Datacenter, которые стоят не дешево, зато они дают право на бесплатное использование определенного числа гостевых ОС. Hyper-V Server сам по себе бесплатен, но все гостевые ОС должны иметь лицензии. Разумеется, речь идет только об ОС Microsoft. Из этого следует, что Hyper-V Server больше всего подходит для виртуализации уже действующей структуры, когда все лицензии уже куплены. Если же планируется развертывание инфраструктуры «с нуля», то Windows Server EE/DC может оказаться предпочтительнее по суммарной стоимости лицензий. Сравнивать с решениями VMWare я не возьмусь, поскольку плохо разбираюсь в их лицензировании. Тем не менее, бесплатный Hyper-V Server не требует покупки дополнительных лицензий на каждую фичу типа Live Migration или бэкапа виртуальных машин «на лету».
На этом хотелось бы закончить – статья и так получилась слишком большой, свое мнение просьба высказывать в комментариях. Спасибо за внимание!
ССЫЛКИ НА ДИСТРИБЫ.
Microsoft® Hyper-V™ Server 2008 R2
StarWind Free iSCSI Target Software
Microsoft iSCSI Software Target 3.3 (если кому приглянется)
Microsoft iSCSI Software Initiator Version 2.08
Hyper-V Remote Management Configuration Utility
Комментариев нет:
Отправить комментарий